
Applying NLP Techniques to Facebook Messenger Data
As the the third and final post in my series on Facebook Messenger analytics (see parts one and two), I wanted to dig a little deeper into the actual content of the messages contained in my dataset. Besides the sentiment analysis and profanity tracking I had already looked into previously, I wanted to see if implementing some more advanced methods could yield any interesting results.
TF-IDF
TF-IDF (Term Frequency - Inverse Document Frequency) is a way of identifying key words within documents that are both important and unique within a context. This is a great single-page resource for the exact equation and its inputs, but the general idea is simple: the more a word is used within a document, the higher of a score it gets. If that word, however, is used often throughout all documents, its score gets penalized. Using the general TF-IDF framework as a reference point, and Maarten Grootendorst’s post on an adjusted formula, I was able to create a way to apply this method to my own data.
What this looks like in practice is combining all messages for a single sender into one massive string. This string is then treated as a document, with the rest of the thread participants as the other documents in the stack. This approach allows me to identify words unique to a user. Extending my example from earlier, here’s a sample of words unique to Sender_6:
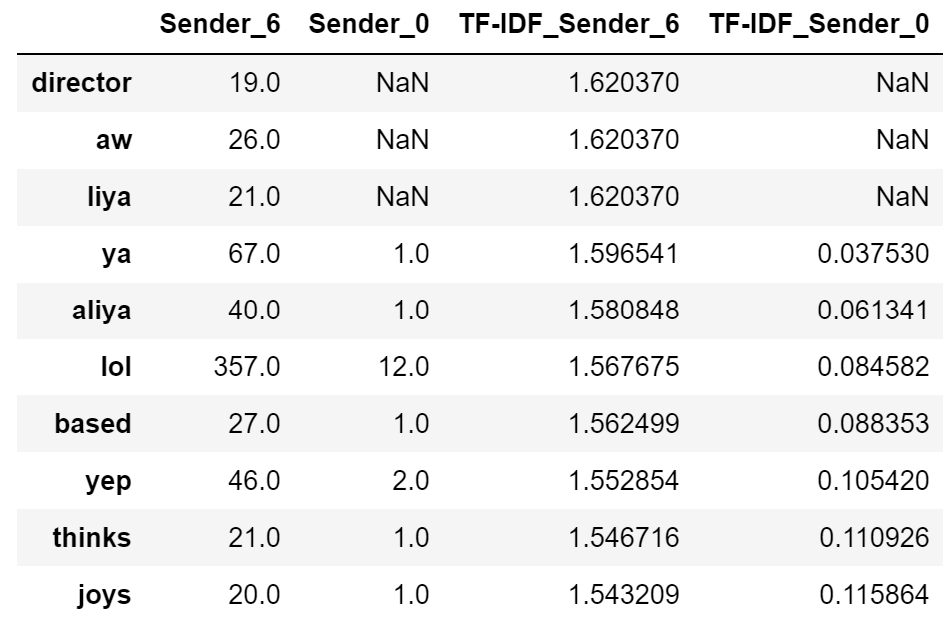
The table just shows the top 10 words by TF-IDF score, filtered down to words used more that 20 times in total. You can see my name/nickname come up twice, as well as a couple idiosyncracies around slang. Sender_6 uses “aw” while I tend to spell it as “aww”, and the same goes for his spelling of “ya” to my “yeah”. Mine shows similar patterns:
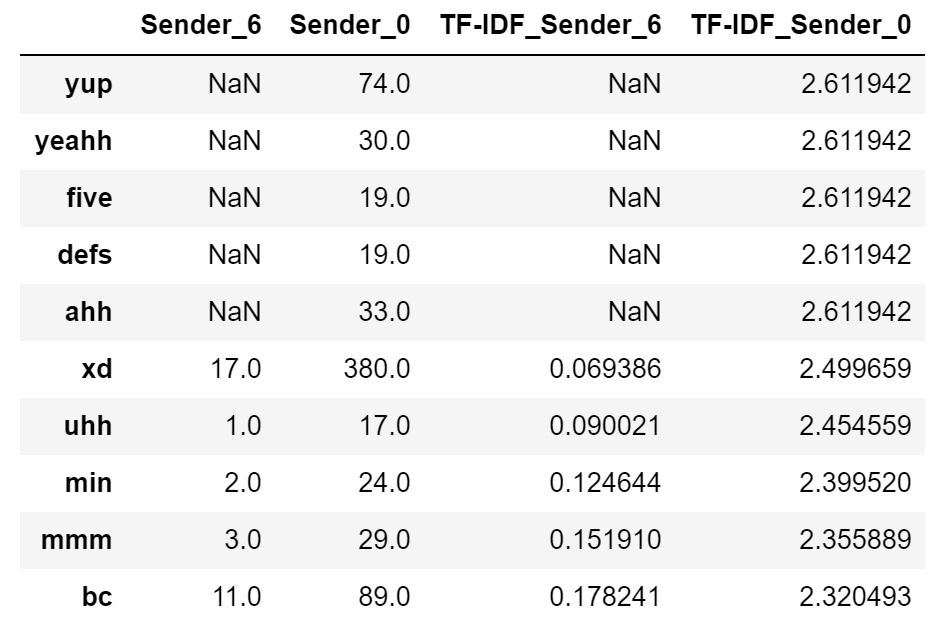
This technique works especially well in groupchats, and could be used as a reliable predictor of identifying a speaker in an anonymous conversation. (Future project idea?)
Top2Vec
I also implemented a new tool we learned in class to identify potential topics within conversations. Top2Vec is a package meant to extract topics from a given block of text. After experimenting a bit, I realized that individual messages aren’t long enough to register specific subjects. Instead, I create new documents by grouping all the texts from a thread per day together (making the assumption that within that thread, we talk about just one thing all day, which is a little unlikely).
I ran this first on my thread with Sender_6, but the results didn’t tell a particularly great story. Most likely, we discuss too many topics within a given day or conversation to point to a reliable prediction. However, on a hunch, I ran this on my longest thread instead. This friend, Sender_2, turned out to have much better results. The output didn’t come in a very visually appealing format, but the results are still compelling:

In more readable terms, Top2Vec identified the following topics:
- Travel (general)
- Work
- Travel (hiking trip-specific)
- Current Events
- Fitness
These are all tangible topics that accurately reflect conversations between myself and Sender_2. Unfortunately, this approach hahs been a hit-or-miss for other threads. Since Facebook Messenger houses conversations as continuous strings of text, Top2Vec has a hard time identifying topic changes within a single day. This is also heavily dependent on the participants of a thread - some conversations are stretched out across multiple days, and some only last minutes before switching to something else.
Conclusion
Both TF-IDF and Top2Vec were easy, straightforward applications of NLP to messaging data. Both provided interesting insights into speech patterns, and have the potential for further analysis.